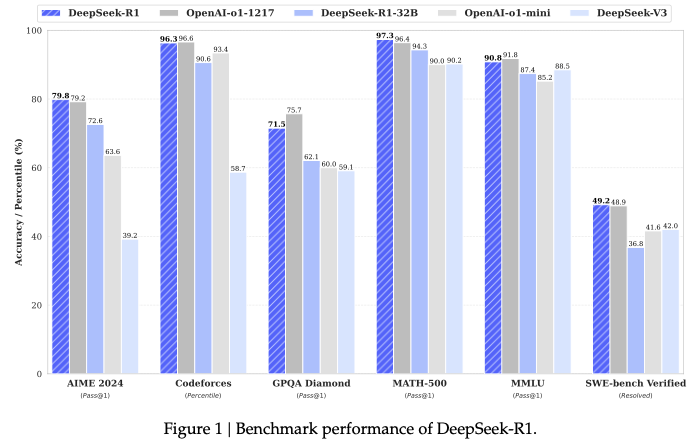
DeepSeek-r1 model series have obtained strong reasoning capability. This blog studies the core of its reinforcement learning based algorithm.
From the above figure, deepseek-r1 obtains on par performance with gpt-o1, which demonstrates the effectiveness of the rl training.
Two models were training, namely deepseek-r1-zero and deepseek-r1. The former one only utilizes an efficient rl algorithm (group relative policy optimization, GRPO), and the latter employs a more sophisticated pipeline involving both sft and rl. But overall, the core factor distinguishing deepseek-r1 series from the rest models is the rl training. In their words, the rl process facilitates “the model’s natural progression”, generating interesting thinking patterns like self-verification, reflection, long CoTs, and the “Aha moment” (Figure below).

They employ Group Relative Policy Optimization (GRPO), which improves the efficiency of PPO via removing the critic model. This is done by estimating the baseline from group scores, reward scores collected from $G$ roll-outs, i.e. ${r_1, r_2, \ldots, r_G}$. The detail of GRPO worths checking, here is the link: https://arxiv.org/pdf/2402.03300.
The second point about their RL training is the reward model. Instead of using reward models (like PRM), they utilize rule-based reward functions like checking the correctness, format, execution results, etc. They mention in section 4.2 about reasons not using a PRM:
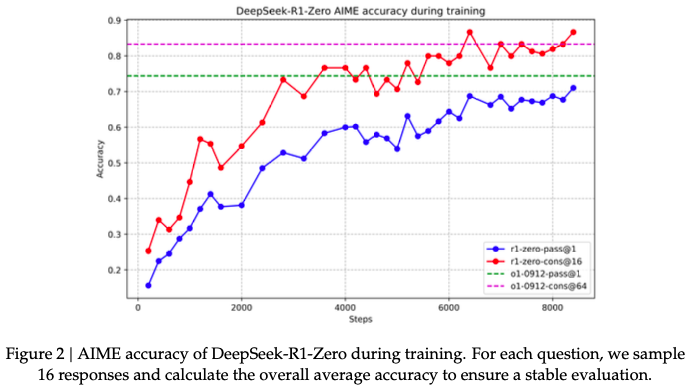
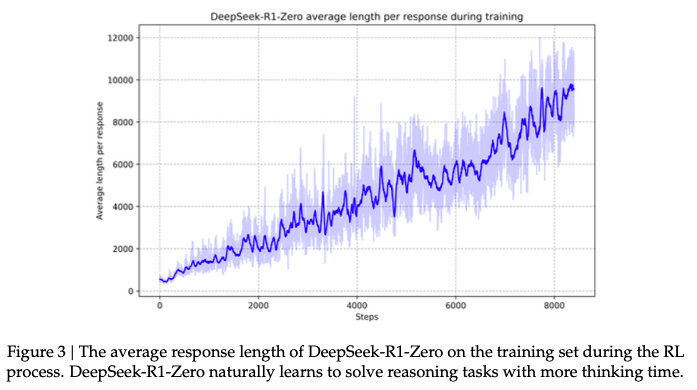
For the training process, they observe a smooth performance improvement, and also a steady increase in response length (figures below). These figures both show the promising performance of GRPO on improving reasoning.
They also distill the trained deepseek-r1 model to smaller models, using Qwen and llama series. The resulting performance is shown below. The resulting smaller models obtain significant performance improvement, and even approach the performance of much larger models like gpt-4o and sonnet-3.5. This is a bit surprising as these smaller models should have much less parametric memory than those of larger models.
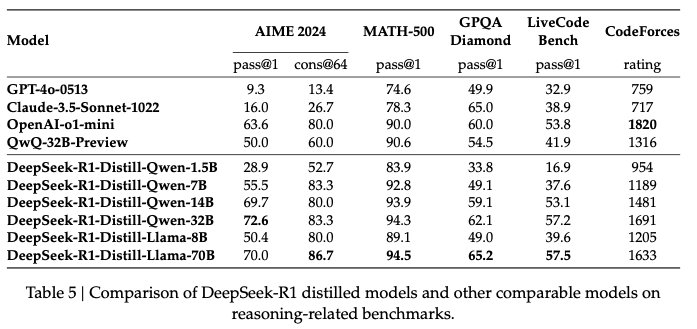
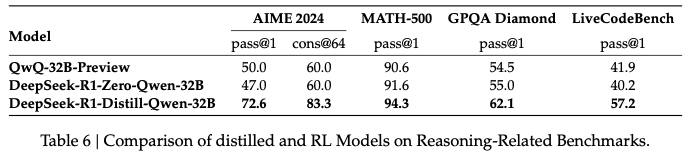
Another interesting result is that when being trained using the rl algorithm directly, smaller models (e.g., Qwen-32B) does not exhibit the superior performance as deepseek-r1. (Results are shown below). On the other hand, if distilled from deepseek-r1, the 32B model observes significant performance improvements. This is a bit concerning. It seems that only sufficiently large models could benefit from the rl process.
They also find that the software engineering tasks (I assume at least one of them must be swebench) do not benefit too much from the rl process as evaluating the roll-out (computing the reward) is expensive.